 |
| Methodology |
|
1. Creating a Map showing the probability of cocaine usage
dependend on Age and Gender |
|
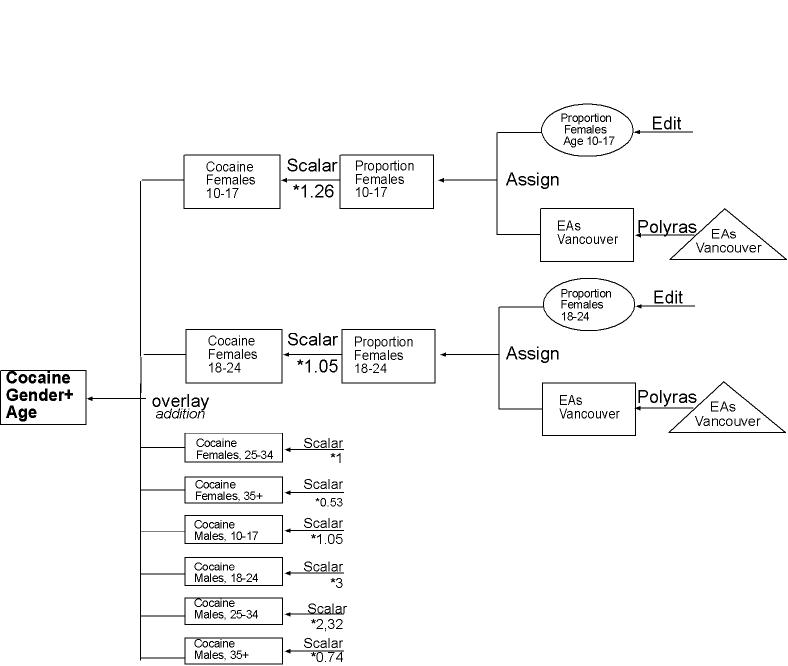
Example-Map for factor age/gender |
|
How did I calculate the Correlation Factors?
I calculated the factors based on
the data in the tables of the National Household Survey.
Example:
Table 4.2 Percentage Reporting Cocaine
Use in the Past Year, by Age Group
The average percentage of Men and
Women through all ages taking Cocaine is 1,9%. I set this average of 1,9%
to '1' and calculated the Weighing Factors by multiplying the data in the
table with 1/1.9.
I calculated Weighing Factors for
Age/Gender, Education and Employmentstate for Heroin, Cocaine and LSD.
|
|
2. Creating a Map showing the probability of Cocaine usage
dependend on Education |
 |
| I used the same procedure to create a mape showing the
probability of Cocaine usage dependent on Education.
Example Map for Factor Education |
|
3. Creating a Map showing the probability of Cocaine usage
dependent on Employment status |
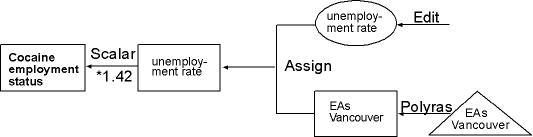 |
Example Map for the factor Employment status
|
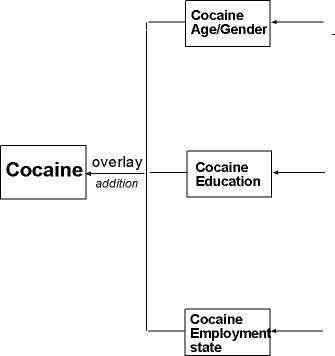
4. Creating a Map showing the probability of Cocaine usage
dependent on Age, Gender, Education and Employment status |
 |
|
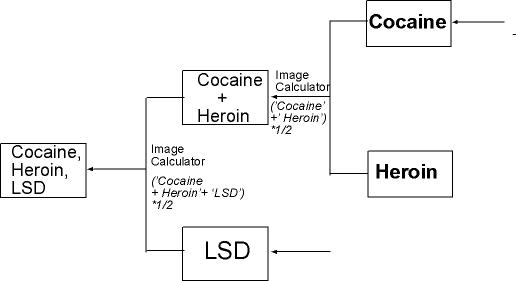
| 5. Creating a Map showing the probability
of Cocaine and Heroin usage
and Cocaine, Heroine and LSD usage |
 |
|
| II. Market Analysis for Dealers |
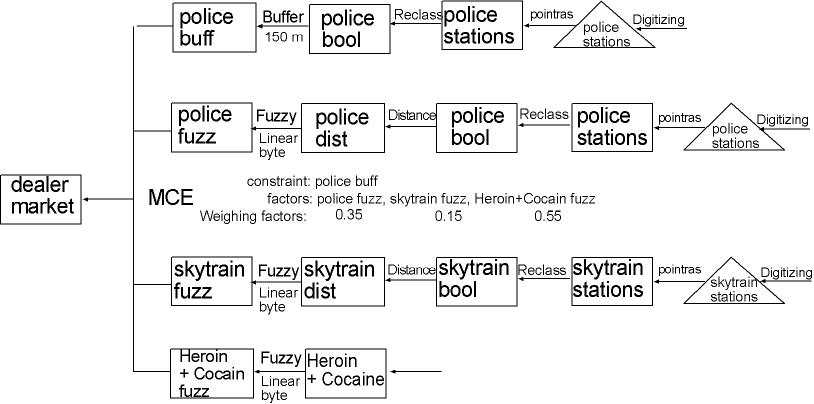 |
(See Maps 1 und 2)
I gave 'Heroin+Cocaine fuzz', the image, that shows the number of customers per area, the factor 0.55, because it is the most important factor. (What does a safe area help if there are no customers?!) Therefore, I gave it an importance of more than 50%. In terms of saftety, I regarded distance to police stations more important than proximity to skytrain stations for two reasons. First, because you will only need the skytrain if you got caught by a police man, which is more likely if you are close to police stations - therefore, distance to police stations should be considered first. Second, there are not enough skytrain stations for to consider the Skytrain as an excellent escape vehicle. For these reasons, I gave the 'police fuzz' a weighing factor of 0.35 and 'skytrain fuzz' 0.15. Map: See Results |
| Back Home Next |
| 1
. Background Research
2 . Data Collection, Preparation, Manipulation 3 . Methodology |
4
. Spatial Analysis
5 . Results & Discussion 6. Problems & Errors |