![]()
![]()
![]()
Reading for Today's Lecture:
Goals of Today's Lecture:
Today's notes
For general composite hypotheses optimality theory is not usually
successful in producing an optimal test. instead we look for
heuristics to guide our choices. The simplest approach is to consider
the likelihood ratio
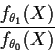
Example 1: In the ![]() problem suppose we
want to test
problem suppose we
want to test ![]() against
against ![]() .
(Remember there is a UMP
test.) The log likelihood function is
.
(Remember there is a UMP
test.) The log likelihood function is
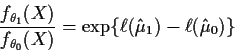
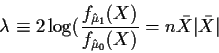
Example 2: In the ![]() problem suppose we
make the null
problem suppose we
make the null ![]() .
Then the value of
.
Then the value of ![]() is simply 0 while
the maximum of the log-likelihood over the alternative
is simply 0 while
the maximum of the log-likelihood over the alternative
![]() occurs at
occurs at ![]() .
This gives
.
This gives
Example 3: For the
![]() problem testing
problem testing
![]() against
against
![]() we must find two estimates of
we must find two estimates of
![]() .
The maximum of the likelihood over the alternative
occurs at the global mle
.
The maximum of the likelihood over the alternative
occurs at the global mle
![]() .
We find
.
We find
We also need to maximize ![]() over the null hypothesis.
Recall
over the null hypothesis.
Recall
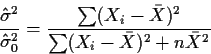
Notice that if n is large we have
This is a general phenomenon when the null hypothesis being tested is of the form ![]() .
Here is the general
theory. Suppose that the vector of p+q parameters
.
Here is the general
theory. Suppose that the vector of p+q parameters ![]() can
be partitioned into
can
be partitioned into
![]() with
with ![]() a vector
of p parameters and
a vector
of p parameters and ![]() a vector of q parameters.
To test
a vector of q parameters.
To test
![]() we find two mles of
we find two mles of ![]() .
First the
global mle
.
First the
global mle
![]() maximizes
the likelihood over
maximizes
the likelihood over
![]() (because typically the probability that
(because typically the probability that ![]() is exactly
is exactly
![]() is 0).
is 0).
Now we maximize the likelihood over the null hypothesis, that is
we find
![]() to maximize
to maximize
Now suppose that the true value of ![]() is
is
![]() (so that the null hypothesis is true). The score function is a
vector of length p+q and can be partitioned as
(so that the null hypothesis is true). The score function is a
vector of length p+q and can be partitioned as
![]() .
The Fisher information matrix can be partitioned as
.
The Fisher information matrix can be partitioned as
![\begin{displaymath}\left[\begin{array}{cc}
I_{\phi\phi} & I_{\phi\gamma}
\\
I_{\phi\gamma} & I_{\gamma\gamma}
\end{array}\right] \, .
\end{displaymath}](img62.gif)
According to our large sample
theory for the mle we have
Theorem: The log-likelihood ratio statistic
Aside:
Theorem: Suppose that
![]() with
with ![]() non-singular and Mis a symmetric matrix. If
non-singular and Mis a symmetric matrix. If
![]() then Xt M X has a
then Xt M X has a ![]() distribution with degrees of freedom
distribution with degrees of freedom
![]() .
.
Proof: We have X=AZ where
![]() and
Z is standard multivariate normal. So
Xt M X = Zt At M A Z.
Let Q=At M A.
Since
and
Z is standard multivariate normal. So
Xt M X = Zt At M A Z.
Let Q=At M A.
Since
![]() the condition in the theorem is actually
the condition in the theorem is actually
The matrix Q is symmetric and so can be written in the form
![]() where
where ![]() is a diagonal matrix containing the
eigenvalues of Q and P is an orthogonal matrix whose columns
are the corresponding orthonormal eigenvectors. It follows that we can
rewrite
is a diagonal matrix containing the
eigenvalues of Q and P is an orthogonal matrix whose columns
are the corresponding orthonormal eigenvectors. It follows that we can
rewrite
We have established that the general distribution of any
quadratic form Xt M X is a linear combination of ![]() variables.
Now go back to the condition QQ=Q. If
variables.
Now go back to the condition QQ=Q. If ![]() is an eigenvalue
of Q and
is an eigenvalue
of Q and ![]() is a corresponding eigenvector then
is a corresponding eigenvector then
![]() but also
but also
![]() .
Thus
.
Thus
![]() .
It follows that either
.
It follows that either ![]() or
or ![]() .
This means
that the weights in the linear combination are all 1 or 0 and that
Xt M X has a
.
This means
that the weights in the linear combination are all 1 or 0 and that
Xt M X has a ![]() distribution with degrees of freedom,
distribution with degrees of freedom, ![]() ,
equal to the number of
,
equal to the number of ![]() which are equal to 1. This is
the same as the sum of the
which are equal to 1. This is
the same as the sum of the ![]() so
so
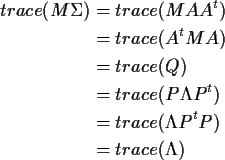
In the application ![]() is
is ![]() the Fisher information and
the Fisher information and
![]() where
where
![\begin{displaymath}J= \left[\begin{array}{cc}
0 & 0 \\ 0 & I_{\gamma\gamma}^{-1}
\end{array}\right]
\end{displaymath}](img99.gif)
![\begin{displaymath}\left[\begin{array}{cc}
I & 0 \\ 0 & 0
\end{array}\right]
\end{displaymath}](img101.gif)