![]()
![]()
![]()
Reading for Today's Lecture:
Goals of Today's Lecture:
Today's notes
A level ![]() confidence set for a parameter
confidence set for a parameter
![]() is a random subset C, of the set of possible values of
is a random subset C, of the set of possible values of ![]() such that for each
such that for each ![]() we have
we have
Suppose C is a level
![]() confidence set for
confidence set for ![]() .
To test
.
To test
![]() we consider the test which rejects if
we consider the test which rejects if
![]() .
This test has level
.
This test has level ![]() .
Conversely, suppose
that for each
.
Conversely, suppose
that for each ![]() we have available a level
we have available a level ![]() test
of
test
of
![]() who rejection region is say
who rejection region is say
![]() .
Then if
we define
.
Then if
we define
![]() we get
a level
we get
a level ![]() confidence for
confidence for ![]() .
The usual t test gives
rise in this way to the usual t confidence intervals
.
The usual t test gives
rise in this way to the usual t confidence intervals
Definition: A pivot (or pivotal quantity) is a function
![]() whose distribution is the same for all
whose distribution is the same for all ![]() .
(As usual
the
.
(As usual
the ![]() in the pivot is the same
in the pivot is the same ![]() as the one being used to
calculate the distribution of
as the one being used to
calculate the distribution of
![]() .
.
Pivots can be used to generate confidence sets as follows. Pick a set
A in the space of possible values for g. Let
![]() ;
since g is pivotal
;
since g is pivotal ![]() is the same for all
is the same for all ![]() .
Now given
a data set X solve the relation
.
Now given
a data set X solve the relation
Example: The quantity
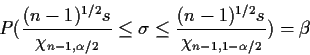
In the same model we also have
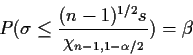
In general the interval from
![]() to
to
![]() has level
has level
![]() .
For a fixed value of
.
For a fixed value of ![]() we can
minimize the length of the resulting interval numerically. This sort of optimization
is rarely used. See your homework for an example of the method.
we can
minimize the length of the resulting interval numerically. This sort of optimization
is rarely used. See your homework for an example of the method.