![]()
![]()
![]()
Reading for Today's Lecture:
Goals of Today's Lecture:
Today's notes
If
![]() are iid Bernoulli(p) then
are iid Bernoulli(p) then
![]() is Binomial(n,p). We used various algebraic tactics to
arrive at the following conclusions:
is Binomial(n,p). We used various algebraic tactics to
arrive at the following conclusions:
This long, algebraically involved, method of proving that
![]() is the UMVUE of p is one special case of
a general tactic.
is the UMVUE of p is one special case of
a general tactic.
In the binomial situation the conditional distribution of the data
![]() given X is the same for all values of
given X is the same for all values of ![]() ;
we
say this conditional distribution is free of
;
we
say this conditional distribution is free of ![]() .
.
Defn: A statistic T(X) is sufficient for the model
![]() if the conditional distribution of the
data X given T=t is free of
if the conditional distribution of the
data X given T=t is free of ![]() .
.
Intuition: Why do the data tell us about ![]() ? Because
different values of
? Because
different values of ![]() give different distributions to X. If two
different values of
give different distributions to X. If two
different values of ![]() correspond to the same joint density or cdf
for X then we cannot, even in principle, distinguish these two values of
correspond to the same joint density or cdf
for X then we cannot, even in principle, distinguish these two values of
![]() by examining X. We extend this notion to the following. If two
values of
by examining X. We extend this notion to the following. If two
values of ![]() give the same conditional distribution of X given Tthen observing T in addition to X does not improve our ability to
distinguish the two values.
give the same conditional distribution of X given Tthen observing T in addition to X does not improve our ability to
distinguish the two values.
Mathematically Precise version of this intuition: If T(X)is a sufficient statistic then we can do the following. If S(X) is any estimate or confidence interval or whatever for a given problem but we only know the value of T then:
You can carry out the first step only if the statistic T is
sufficient; otherwise you need to know the true value of ![]() to
generate X*.
to
generate X*.
Example 1:
![]() iid Bernoulli(p).
Given
iid Bernoulli(p).
Given
![]() the indexes of the y successes have the
same chance of being any one of the
the indexes of the y successes have the
same chance of being any one of the
![]() possible subsets of
possible subsets of
![]() .
This chance does not depend on p so
.
This chance does not depend on p so
![]() is a sufficient statistic.
is a sufficient statistic.
example 2: If
![]() are iid
are iid ![]() then
the joint distribution of
then
the joint distribution of
![]() is multivariate
normal with mean vector whose entries are all
is multivariate
normal with mean vector whose entries are all ![]() and variance covariance
matrix which can be partitioned as
and variance covariance
matrix which can be partitioned as
![\begin{displaymath}\left[\begin{array}{cc} I_{n \times n} & {\bf 1}_n /n
\\
{\bf 1}_n^t /n & 1/n \end{array}\right]
\end{displaymath}](img22.gif)
You can now compute the conditional means and variances of Xi given
![]() and use the fact that the conditional law is multivariate
normal to prove that the conditional distribution of the data given
and use the fact that the conditional law is multivariate
normal to prove that the conditional distribution of the data given
![]() is multivariate normal with mean vector all of whose
entries are x and variance-covariance matrix given
by
is multivariate normal with mean vector all of whose
entries are x and variance-covariance matrix given
by
![]() .
Since this does not depend
on
.
Since this does not depend
on ![]() we find that
we find that
![]() is sufficient.
is sufficient.
WARNING: Whether or not a statistic is sufficient depends on
the density function and on ![]() .
.
Theorem: Suppose that S(X) is a sufficient statistic
for some model
![]() .
If T is an
estimate of some parameter
.
If T is an
estimate of some parameter
![]() then:
then:
Proof: First review conditional distributions: abstract definition of conditional expectation is
Defn: E(Y|X) is any function of X such that
Defn: E(Y|X=x) is a function g(x) such that
Fact: If X,Y has joint density
fX,Y(x,y) and
conditional density f(y|x) then
Proof of Fact:
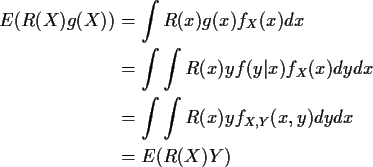
You should simply think of E(Y|X) as being what you get when you average Y holding X fixed. It behaves like an ordinary expected value but where functions of X only are like constants.
Proof of the Rao Blackwell Theorem
Step 1: The definition of sufficiency is that the
conditional distribution of X given S does not depend on
![]() .
This means that E(T(X)|S) does not depend on
.
This means that E(T(X)|S) does not depend on ![]() .
.
Step 2: This step hinges on the following identity
(called Adam's law by Jerzy Neyman - he used to say it comes
before all the others)
From this we deduce that
Step 3:
This relies on the following very useful decomposition.
(In regression courses we say that the total sum of squares
is the sum of the regression sum of squares plus the
residual sum of squares.)
![\begin{eqnarray*}{\rm Var}(E(Y\vert X)) & = &E[(E(Y\vert X)-E[E(Y\vert X)])^2]
\\
& = & E[(E(Y\vert X)-E(Y))^2]
\end{eqnarray*}](img42.gif)
![\begin{multline*}E\left[Y^2 -2YE[Y\vert X]+2(E[Y\vert X])^2 \right.\\
\left.-2E(Y)E[Y\vert X] + E^2(Y)\right]
\end{multline*}](img44.gif)
![\begin{eqnarray*}E[(E[Y\vert X])^2] & = & E[E[YE(Y\vert X)\vert X]]
\\ & = & E[YE(Y\vert X)]
\end{eqnarray*}](img46.gif)
We apply this to the Rao Blackwell theorem
to get
Examples:
In the binomial problem
Y1(1-Y2) is an unbiased
estimate of p(1-p). We improve this by computing
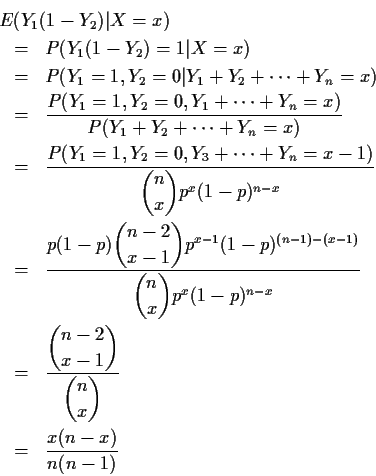
Example: If
![]() are iid
are iid ![]() then
then
![]() is sufficient and X1 is an unbiased estimate of
is sufficient and X1 is an unbiased estimate of ![]() .
Now
.
Now
![\begin{align*}E(X_1\vert\bar{X})& = E[X_1-\bar{X}+\bar{X}\vert\bar{X}]
\\
& = E[X_1-\bar{X}\vert\bar{X}] + \bar{X}
\\
& = \bar{X}
\end{align*}](img52.gif)
which is the UMVUE.
In the binomial example the log likelihood (at least the part depending
on the parameters) was seen above to be a function of X (and not
of the original data
![]() as well). In the normal example
the log likelihood is, ignoring terms which don't contain
as well). In the normal example
the log likelihood is, ignoring terms which don't contain ![]() ,
,
These are examples of the Factorization Criterion:
Theorem: If the model for data X has density
![]() then the statistic S(X) is sufficient if and only if the density can be
factored as
then the statistic S(X) is sufficient if and only if the density can be
factored as
Proof: Find statistic T(x) such that
X is a one to one function of the pair S,T. Apply
change of variables to fS,T. If
![]() factors then
factors then
Example: If
![]() are iid
are iid
![]() the joint density is
the joint density is
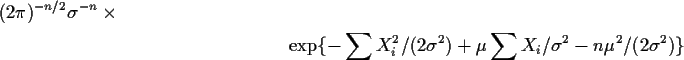
which is evidently a function of