![]()
![]()
![]()
Reading for Today's Lecture:
Goals of Today's Lecture:
Today's notes
Suppose T is and unbiased estimate of ![]() .
Then
.
Then
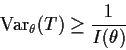
Summary of Implications
What can we do to find UMVUEs when the CRLB is a strict inequality?
Example: Suppose X has a Binomial(n,p) distribution.
The score function is
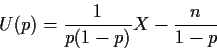
Different tactic: Suppose
T(X) is some unbiased function of X. Then we have
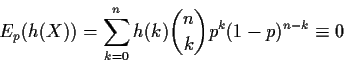
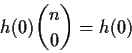
A Binomial random variable is a sum of n iid Bernoulli(p)rvs. If
![]() iid Bernoulli(p) then
iid Bernoulli(p) then
![]() is Binomial(n,p). Could we do better by than
is Binomial(n,p). Could we do better by than
![]() by trying
by trying
![]() for some other function T?
for some other function T?
Try n=2. There are 4 possible values for
Y1,Y2. If
h(Y1,Y2) = T(Y1,Y2) - [Y1+Y2]/2 then
![\begin{eqnarray*}E_p( h(Y_1,Y_2)) &= & h(0,0)(1-p)^2
\\
&& +
[h(1,0)+h(0,1)]p(1-p)
\\
&& + h(1,1) p^2 \, .
\end{eqnarray*}](img23.gif)
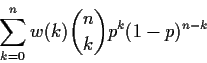
![\begin{align*}{\rm Var(T)} = & E_p( [T(Y_1,\ldots,Y_n) - p]^2)
\\
=& E_p( [T(...
...\\
& 2E_p( [T(Y_1,\ldots,Y_n)
-X/n][X/n-p])
\\ & + E_p([X/n-p]^2)
\end{align*}](img27.gif)
![\begin{multline*}E_p( [T(Y_1,\ldots,Y_n)-X/n][X/n-p])
\\
=\sum_{y_1,\ldots,y_n...
..._i/n][\sum y_i/n -p]
\\
\times p^{\sum y_i} (1-p)^{n-\sum
y_i}
\end{multline*}](img29.gif)
![\begin{multline*}E_p( [T(Y_1,\ldots,Y_n)-X/n][X/n-p])
\\
= \sum_{x=0}^n
\sum...
...y_1,\ldots,y_n)-x/n]\right][x/n -p]
\\
\times p^{x}
(1-p)^{n-x}
\end{multline*}](img30.gif)
We have already shown that the sum in [] is 0!
This long, algebraically involved, method of proving that
![]() is the UMVUE of p is one special case of
a general tactic.
is the UMVUE of p is one special case of
a general tactic.
To get more insight I begin by rewriting
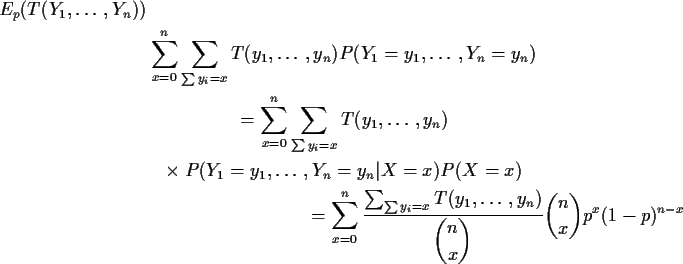
Notice large fraction in formula is average value
of T over values of y when ![]() is held fixed at x. Notice
that the weights in this average do not depend on p. Notice that
this average is actually
is held fixed at x. Notice
that the weights in this average do not depend on p. Notice that
this average is actually
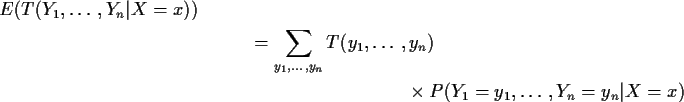
Notice conditional probabilities do not depend on p. In a
sequence of Binomial trials if I tell you that 5 of 17 were heads and the
rest tails the actual trial numbers of the 5 Heads are chosen at random
from the 17 possibilities; all of the 17 choose 5 possibilities have the
same chance and this chance does not depend on p.
Notice: with data
![]() log likelihood
is
log likelihood
is
In the binomial situation the conditional distribution of the data
![]() given X is the same for all values of
given X is the same for all values of ![]() ;
we
say this conditional distribution is free of
;
we
say this conditional distribution is free of ![]() .
.
Defn: Statistic T(X) is sufficient for the model
![]() if conditional distribution of
data X given T=t is free of
if conditional distribution of
data X given T=t is free of ![]() .
.
Intuition: Data tell us about ![]() if
different values of
if
different values of ![]() give different distributions to X. If two
different values of
give different distributions to X. If two
different values of ![]() correspond to same density or cdf
for X we cannot distinguish these two values of
correspond to same density or cdf
for X we cannot distinguish these two values of
![]() by examining X. Extension of this notion: if two
values of
by examining X. Extension of this notion: if two
values of ![]() give same conditional distribution of X given Tthen observing T in addition to X doesn't improve our ability to
distinguish the two values.
give same conditional distribution of X given Tthen observing T in addition to X doesn't improve our ability to
distinguish the two values.
Mathematically Precise version of this intuition: Suppose T(X)is sufficient statistic and S(X) is any estimate or confidence interval or ... If you only know value of T then:
You can carry out the first step only if the statistic T is
sufficient; otherwise you need to know the true value of ![]() to
generate X*.
to
generate X*.
Example 1:
![]() iid Bernoulli(p).
Given
iid Bernoulli(p).
Given
![]() the indexes of the y successes have the
same chance of being any one of the
the indexes of the y successes have the
same chance of being any one of the
![]() possible subsets of
possible subsets of
![]() .
This chance does not depend on p so
.
This chance does not depend on p so
![]() is a sufficient statistic.
is a sufficient statistic.
Example 2:
![]() iid
iid ![]() .
Joint distribution of
.
Joint distribution of
![]() is multivariate
normal. All entries of mean vector are
is multivariate
normal. All entries of mean vector are ![]() .
Variance covariance
matrix can be partitioned as
.
Variance covariance
matrix can be partitioned as
![\begin{displaymath}\left[\begin{array}{cc} I_{n \times n} & {\bf 1}_n /n
\\
{\bf 1}_n^t /n & 1/n \end{array}\right]
\end{displaymath}](img43.gif)
You can now compute the conditional means and variances of Xi given
![]() and use the fact that the conditional law is multivariate
normal to prove that the conditional distribution of the data given
and use the fact that the conditional law is multivariate
normal to prove that the conditional distribution of the data given
![]() is multivariate normal with mean vector all of whose
entries are x and variance-covariance matrix given
by
is multivariate normal with mean vector all of whose
entries are x and variance-covariance matrix given
by
![]() .
Since this does not depend
on
.
Since this does not depend
on ![]() we find that
we find that
![]() is sufficient.
is sufficient.
WARNING: Whether or not statistic is sufficient depends on
density function and on ![]() .
.
Theorem: [Rao-Blackwell] Suppose S(X) is a sufficient statistic
for model
![]() .
If T is an
estimate of
.
If T is an
estimate of
![]() then:
then:
Proof: Review conditional distributions: abstract definition of conditional expectation is:
Defn: E(Y|X) is any function of X such that
Fact: If X,Y has joint density
fX,Y(x,y) and
conditional density f(y|x) then
Proof:
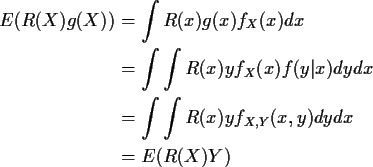
Think of E(Y|X) as average Y holding X fixed. Behaves like ordinary expected value but functions of X only are like constants.