![]()
![]()
![]()
Reading for Today's Lecture:
Goals of Today's Lecture:
Today's notes
Method of Moments
Basic strategy: set sample moments equal to population moments and solve for the parameters.
Gamma Example
The Gamma(
![]() )
density is
)
density is
![\begin{displaymath}f(x;\alpha,\beta) =
\frac{1}{\beta\Gamma(\alpha)}\left(\frac{...
...ta}\right)^{\alpha-1}
\exp\left[-\frac{x}{\beta}\right] 1(x>0)
\end{displaymath}](img3.gif)
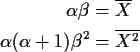
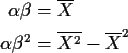
These equations are much easier to solve than the likelihood equations. The
latter
involve the function
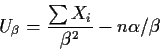
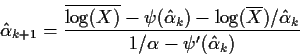
Why bother doing the Newton Raphson steps? Why not just use the method of moments estimates? The answer is that the method of moments estimates are not usually as close to the right answer as the mles.
Rough principle: Good estimate
![]() of
of ![]() is usually
close to
is usually
close to ![]() if the true value,
if the true value, ![]() ,
of
,
of ![]() .
Closer
estimates, more often, are better estimates.
.
Closer
estimates, more often, are better estimates.
Principle must be quantified to ``prove'' that the mle is a good estimate. In the Neyman Pearson spirit we measure average closeness.
Definition: The Mean Squared Error (MSE) of an estimator
![]() is the function
is the function
Standard identity:
Primitive example: I take a coin from my pocket and toss it
6 times. I get HTHTTT. The MLE of the probability of heads is
Alternative estimate is
![]() :
ignores data, guesses coin is fair.
MSEs are
:
ignores data, guesses coin is fair.
MSEs are
Now suppose I did the same experiment with a thumbtack. The tack
can land point up (U) or tipped over (O). If I get
UOUOOO how should I estimate p the probability of U? The
mathematics is identical to the above but it seems clear that
there is less reason to think ![]() is better than
is better than ![]() since there is less reason to believe
since there is less reason to believe
![]() than
with a coin.
than
with a coin.
The problem above illustrates a general phenomenon. An estimator can
be good for some values of ![]() and bad for others. When comparing
and bad for others. When comparing
![]() and
and
![]() ,
two estimators of
,
two estimators of ![]() we will say
that
we will say
that
![]() is better than
is better than
![]() if it has uniformly
smaller MSE:
if it has uniformly
smaller MSE:
The definition raises the question of the existence of a best
estimate - one which is better than every other estimator. There is
no such estimate. Suppose
![]() were such a best estimate. Fix
a
were such a best estimate. Fix
a ![]() in
in ![]() and let
and let
![]() .
Then the
MSE of
.
Then the
MSE of ![]() is 0 when
is 0 when
![]() .
Since
.
Since
![]() is
better than
is
better than ![]() we must have
we must have
Principle of Unbiasedness: A good estimate is unbiased, that is,
WARNING: In my view the Principle of Unbiasedness is a load of hog wash.
For an unbiased estimate the MSE is just the variance.
Definition: An estimator ![]() of a parameter
of a parameter
![]() is
Uniformly Minimum Variance Unbiased (UMVU) if, whenever
is
Uniformly Minimum Variance Unbiased (UMVU) if, whenever
![]() is an unbiased estimate of
is an unbiased estimate of ![]() we have
we have
The point of having
![]() is to study problems like estimating
is to study problems like estimating
![]() when you have two parameters like
when you have two parameters like ![]() and
and ![]() for example.
for example.
If
![]() we can derive some information from the
identity
we can derive some information from the
identity
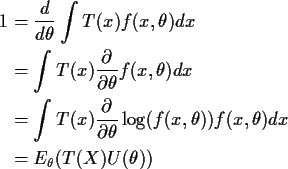
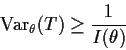
Summary of Implications