STAT 330 Lecture 19
Reading for Today's Lecture: 10.1.
Goals of Today's Lecture:
Today's notes
I samples
Data:
![]() is observation j in sample i, for
is observation j in sample i, for ![]() and
i from 1 to I.
and
i from 1 to I.
Jargon: ``I levels of some factor influencing the response variable X.''
Model:
First problem of interest: give hypothesis tests for ![]() .
.
Technique: ANalysis Of VAriance or ANOVA.
Idea: Compare two independent estimates of ![]() using an F test.
using an F test.
The theory:
1: Mean Square for Error or MSE is
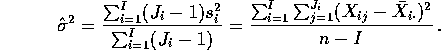
where ![]() is the total number of observations in all the samples
and
I is the number of samples.
is the total number of observations in all the samples
and
I is the number of samples.
2: Two motivations for the second estimate of ![]() :
:
A: If ![]() and all the
and all the ![]() then
then
![]() are an iid sample of size I
from
a population which has a
are an iid sample of size I
from
a population which has a ![]() distribution. The
sample
variance of the
distribution. The
sample
variance of the ![]() is
is
![]()
where now
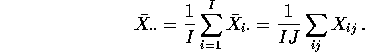
This sample variance is an estimate of the population variance ![]() and
can be used to estimate
and
can be used to estimate ![]() by multiplying by J to get
by multiplying by J to get
![]()
This quantity is called the Mean Square for Treatment (MSTr) or the Mean Square Between Groups. The numerator is called the Sum of Squares for Treatments

The last two formulas work even when the sample sizes ![]() are not all
equal.
Our test of
are not all
equal.
Our test of ![]() is based on the ratio of these
two variance estimates:
is based on the ratio of these
two variance estimates:
![]()
Fact: If ![]() is true then
is true then
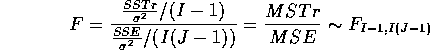
B: Alternative motivation for the test:
![]()
where we define
![]()
A natural estimate of ![]() is
is
![]()
(we are just plugging in sample means for population means).
BUT: we can compute the expected value of this estimate and get
![]()
so that the natural estimate tends to be a bit more than what we want to
estimate. We divide by an estimate of ![]() , namely,
(I-1)MSE/J to get
, namely,
(I-1)MSE/J to get
![]()
as an estimate of
![]()
Thus the null hypothesis predicts ![]() while the alternative
predicts F>1; we will reject
while the alternative
predicts F>1; we will reject ![]() for large values of F.
for large values of F.
ANOVA Tables
We generally record the arithmetic of our analysis in a table called an ANOVA table.
| Sum of | Mean | Expected | ||||
| Source | df | Squares | Square | F | P | Mean Square |
| | I-1 | | | |
| |
|
| I(J-1) | | | |||
| Total | IJ-1 | |
Remark: The only easily interpreted number in this table is the P value.
Remark: A central point of ANOVA tables is that the columns labelled df and Sum of Squares each add up to the Total line.
Remark: The table is traditionally filled in by calculating two lines and filling in the rest by subtraction. This is no longer relevant in a computer age. It is no longer relevant to give the short cut formulas for computing the sums of squares by hand (see top of page 398 in text for formulas involving subtraction of two squares).
Why does the table add up?
Pythagoras's Theorem:
If x and y are perpendicular vectors in ![]() then
then
![]()
The sum of squares decomposition in one example
The data consist of blood coagulation times for 24 animals fed one of 4 different diets. In the following I write the data in a table and decompose the table into a sum of several tables. The 4 columns of the table correspond to Diets A, B, C and D. Later in the course we will do matrix linear algebra and then want to think of stacking up these 24 values into a single column vector but the tables save space.
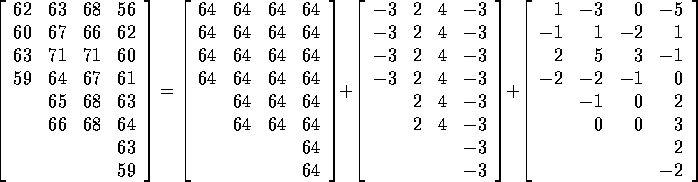
The sums of squares of the entries of each of these arrays are
intervals for differences between the 4 population means.
On the left hand side ![]() . This is the
uncorrected total sum of squares. The first term
on the right hand side gives
. This is the
uncorrected total sum of squares. The first term
on the right hand side gives ![]() . This term
is sometimes put in ANOVA tables as the Sum of Squares due to the
Grand Mean but it is usually subtracted from the total to produce the
Total Sum of Squares we usually put at the bottom of the table
and often called the Corrected (or Adjusted) Total Sum of Squares.
In this case the corrected sum of squares is the squared
length of the table
. This term
is sometimes put in ANOVA tables as the Sum of Squares due to the
Grand Mean but it is usually subtracted from the total to produce the
Total Sum of Squares we usually put at the bottom of the table
and often called the Corrected (or Adjusted) Total Sum of Squares.
In this case the corrected sum of squares is the squared
length of the table
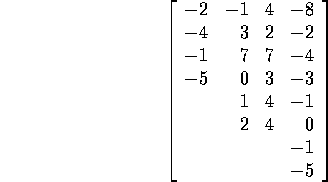
which is 340.
The second term on the right hand side of the equation has squared length
![]() (which is the Treatment
Sum of Squares produced by SAS). The formula for this Sum of Squares is
(which is the Treatment
Sum of Squares produced by SAS). The formula for this Sum of Squares is
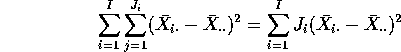
but I want you to see that the formula is
just the squared length of the vector of individual sample means minus
the grand mean. The last vector of the decomposition is called
the residual vector and has squared length ![]() . Corresponding to the decomposition of the total squared length
of the data vector is a decomposition of its dimension, 24, into the
dimensions of subspaces. For instance the grand mean is always a multiple
of the single vector all of whose entries are 1; this describes
a one dimensional space. The second vector, of deviations from a grand
mean lies in the three dimensional subspace of tables which are constant
in each column and have a total equal to 0. Similarly the vector of
residuals lies in a 20 dimensional subspace - the set of all tables whose
columns sum to 0. This decomposition of dimensions is the decomposition
of degrees of freedom. So 24 = 1+3+20 and the degrees of freedom for
treatment and error are 3 and 20 respectively. The vector whose squared
length is the Corrected Total Sum of Squares lies in the 23 dimensional
subspace of vectors whose entries sum to 1; this produces the 23 total
degrees of freedom in the usual ANOVA table.
. Corresponding to the decomposition of the total squared length
of the data vector is a decomposition of its dimension, 24, into the
dimensions of subspaces. For instance the grand mean is always a multiple
of the single vector all of whose entries are 1; this describes
a one dimensional space. The second vector, of deviations from a grand
mean lies in the three dimensional subspace of tables which are constant
in each column and have a total equal to 0. Similarly the vector of
residuals lies in a 20 dimensional subspace - the set of all tables whose
columns sum to 0. This decomposition of dimensions is the decomposition
of degrees of freedom. So 24 = 1+3+20 and the degrees of freedom for
treatment and error are 3 and 20 respectively. The vector whose squared
length is the Corrected Total Sum of Squares lies in the 23 dimensional
subspace of vectors whose entries sum to 1; this produces the 23 total
degrees of freedom in the usual ANOVA table.