Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| PROC CAPABILITY and General Statements |
You can use the NORMALTEST option in the PROC CAPABILITY statement to request several tests of the hypothesis that the analysis variable values are a random sample from a normal distribution. These tests, which are summarized in the table labeled Tests for Normality, include the following:
Tests for normality are particularly important in process capability analysis because the commonly used capability indices are difficult to interpret unless the data are at least approximately normally distributed. Furthermore, the confidence limits for capability indices displayed in the table labeled Process Capability Indices require the assumption of normality. Consequently, the tests of normality are always computed when you specify the SPEC statement, and a note is added to the table when the hypothesis of normality is rejected. You can specify the particular test and the significance level with the CHECKINDICES option.
Small values of W lead to rejection of the null hypothesis. The method for computing the p-value (the probability of obtaining a W statistic less than or equal to the observed value) depends on n. For n=3, the probability distribution of W is known and is used to determine the p-value. For n>4, a normalizing transformation is computed:

The empirical distribution function is defined for a set of n independent observations X1, ... ,Xn with a common distribution function F(x). Under the null hypothesis, F(x) is the normal distribution. Denote the observations ordered from smallest to largest as X(1), ... ,X(n). The empirical distribution function, Fn(x), is defined as
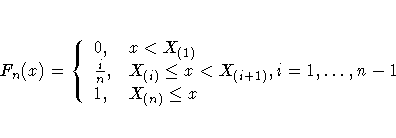
Note that Fn(x) is a step function that takes a step of height [1/n] at each observation. This function estimates the distribution function F(x). At any value x, Fn(x) is the proportion of observations less than or equal to x, while F(x) is the probability of an observation less than or equal to x. EDF statistics measure the discrepancy between Fn(x) and F(x).
The EDF tests make use of the probability integral transformation U=F(X). If F(X) is the distribution function of X, the random variable U is uniformly distributed between 0 and 1. Given n observations X(1), ... ,X(n), the values U(i)=F(X(i)) are computed. These values are used to compute the EDF test statistics, as described in the next three sections. The CAPABILITY procedures computes the associated p-values by interpolating internal tables of probability levels similar to those given by D'Agostino and Stephens (1986).

The Kolmogorov-Smirnov statistic is computed as the maximum of D+ and D-, where D+ is the largest vertical distance between the EDF and the distribution function when the EDF is greater than the distribution function, and D- is the largest vertical distance when the EDF is less than the distribution function.

PROC CAPABILITY uses a modified Komogorov D statistic to test the data against a normal distribution with mean and variance equal to the sample mean and variance.
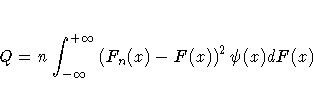
The Anderson-Darling statistic (A2) is defined as
![A^2 = n\int_{-\infty}^{+\infty}(F_n(x)-F(x))^2
[F(x)(1-F(x))]^{-1} dF(x)](images/capeq47.gif)
The Anderson-Darling statistic is computed as
![A^2 = -n-\frac{1}n\sum_{i=1}^n
[(2i-1)\log U_{(i)} + (2n+1-2i)
\log(\{1-U_{(i)})]](images/capeq49.gif)

The Cram![]() r-von Mises statistic is computed as
r-von Mises statistic is computed as

|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.