Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| Regression |
Logistic regression enables you to investigate the relationship between a categorical outcome and a set of explanatory variables. The outcome, or response, can be dichotomous (yes, no) or ordinal (low, medium, high). When you have a dichotomous response, you are performing standard logistic regression. When you are modeling an ordinal response, you are fitting a proportional odds model.
You can express the logistic model for describing the variation among
probabilities ![]() as
as
![\theta_{h} & = & \{1 + \exp [- \alpha - \sum_{k=1}^t {\beta}_{k} x_{hk} ] \}^{-1}](images/a11eq4.gif)
where ![]() is the intercept parameter,
is the intercept parameter,
![]() is a vector of t regression parameters, and
x'h is a row vector of explanatory variables
corresponding to the hth subpopulation.
is a vector of t regression parameters, and
x'h is a row vector of explanatory variables
corresponding to the hth subpopulation.
You can show that the odds of success for the hth group are

By taking logs on both sides, you obtain a linear model for the logit:

This is the log odds of success to failure for the hth subpopulation.
A nice property of the logistic model is that all possible values
of ![]() in
in ![]() map into
(0,1) for
map into
(0,1) for ![]() . Note that
. Note that ![]() are the odds ratios.
Maximum likelihood methods are used to estimate
are the odds ratios.
Maximum likelihood methods are used to estimate ![]() and
and
![]()
In a study on the presence of coronary artery disease, walk-in patients at a clinic were examined for symptoms of coronary artery disease. Investigators also administered an ECG. Interest lies in determining whether there is a relationship between presence or absence of coronary artery disease and ECG score and gender of patient. Logistic regression is the appropriate tool for such an investigation.
The data set analyzed in this example is called Coronary2. It contains the following variables:
The task includes performing a logistic analysis to determine an appropriate model.
Note that Model Pr{ }: determines which value of the dependent variable the model is based on; usually, the value representing an event (such as yes or success) is chosen.
Figure 11.13 displays the resulting dialog.

|
To specify a forward selection model with main effects and their interactions, follow these steps:

|
Figure 11.14 displays the Model dialog with the terms age, ecg, sex, and their interactions selected as effects in the model.
Note that you can build specific models with the Add, Cross, and Factorial buttons, or you can select a model by clicking on the Standard Models button and making a selection from the pop-up list. From this list, you can request that your model include main effects only or effects up to two-way interactions.
Now, to specify your model-building technique, follow these steps:

|
Figure 11.15 displays the Include tab with the terms age, ecg, and sex selected as model terms to be included in every model.
When you have completed your selections, click OK in the main dialog to produce your analysis.

|
When the explanatory variables in a logistic regression are relatively small in number and are qualitative, you can request a goodness-of-fit test. However, when you also have quantitative variables, the sample size requirements for these tests are not met. An alternative strategy for testing goodness of fit in this case is to examine the residual score statistic. This criterion is based on the relationship of the residuals of the model with other potential explanatory variables. If an association exists, then the additional explanatory variable should also be included in the model. This test is distributed as chi-square, with degrees of freedom equal to the difference in the number of parameters in the original model and the number of parameters in the expanded model.
The residual score statistic is displayed in Figure 11.16 as the "Residual Chi-Square Test" table. Since the difference in the number of parameters for the expanded model and the original model is 9 - 4 = 5, the score statistic has 5 degrees of freedom. Since the value of the statistic is 2.24 and the p-value is 0.81, the main effects model fits adequately and no additional interactions need to be added.
The "Type III Tests of Effects" table provides Wald chi-square
statistics that indicate that both age and sex are clearly
significant at the ![]() level of significance. The
ecg variable approaches significance, with the Wald
statistic of 5.67 and p = 0.059. Although you may want to delete
the ecg variable because it does not meet the
level of significance. The
ecg variable approaches significance, with the Wald
statistic of 5.67 and p = 0.059. Although you may want to delete
the ecg variable because it does not meet the ![]() significance criteria, there may be reasons for keeping it.
significance criteria, there may be reasons for keeping it.
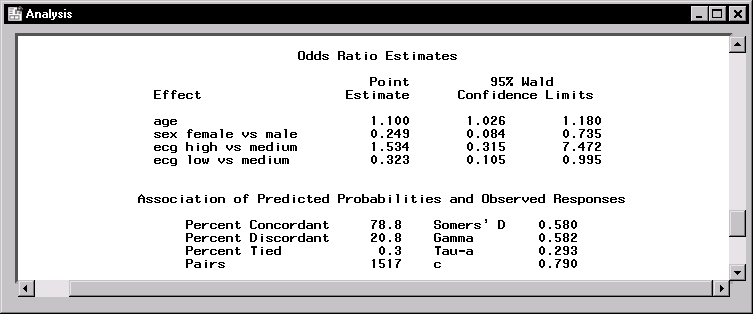
|
Figure 11.17 displays odds ratio estimates and statistics describing the association of predicted probabilities and observed responses. The value of 1.10 for age is the extent to which the odds of coronary heart disease increase each year. The odds ratio for sex, 0.249, is the odds for females relative to males adjusted for age and ecg. Thus, the odds of coronary heart diseases for females are approximately one-fourth that of males.
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.