Introduction to Machine Learning¶
in these notes, much of the introductory information was taken from the book Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
- this book is much more practical than the textbook, showing how to use popular Python libraries to solve machine learning problems
- the course textbook is much more theory and research-oriented
Introduction¶
[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed. – Arthur Samuel, 1959
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience. – Tom Mitchell, 1997
machine learning (ML) is a huge topic
in the last few years, it has gained mainstream use thanks to breakthroughs in so-called “deep” learning, and also the rise of data science (which provides lots of data that can be learned from)
machine learning is often a reasonable choice for solving these sorts of problems:
- problems that require lots of hand-tuning or a large number of rules
- complex problems where traditional “by hand” approaches don’t exist
- just because a traditional algorithm doesn’t exist for solving a problem doesn’t mean that there is a necessarily a good ML solution: you still need to find the right ML approach, which usually takes some experimentation
- fast-changing environments, e.g. in cases where a program needs to update its rules more quickly than humans can update them
- getting insights into big data, e.g. ML can help find patterns that lead to better understanding
Example of Machine Learning: Spam Filtering¶
given an email E, a spam filter must classify E either as ham (good) or spam (bad)
it’s possible to create a spam filter with hand-crafted rules, but:
- you will need lots and lots of rules: huge, complex programs!
- spam creators change their tactics over time, and so you will constantly need to be updating your rules
modern spam filters learn rules for detecting spam
the general pattern is this (Figure 1-2 of Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems):
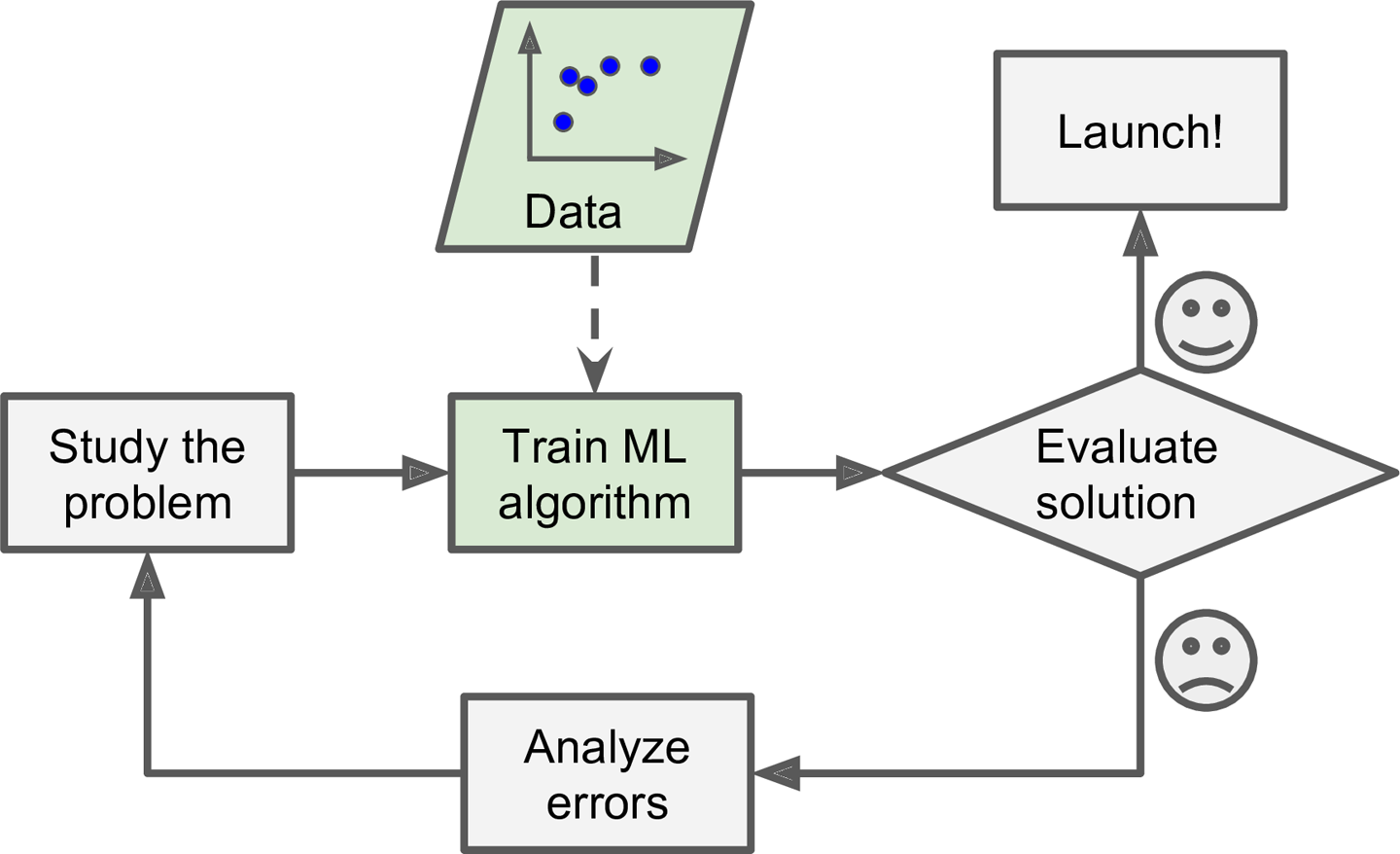
this process of training, evaluating, and updating the spam filter can be automated, so that everyone time the user marks email as spam the system can update it rule
Example of Machine Learning: Speech Recognition¶
recognizing human speech is another application where machine learning shines
e.g. suppose you want to recognize the difference between the spoken words “one” and “two”
“two” starts with a high-pitch “T” sound, and so you might create a hand-written rule that uses that fact to distinguish “one” and “two”
but creating hand-written rules like this does not scale to the thousands and thousands of words spoken by people, all with different voices, different accents, and in environments with different amounts of noise
the best speech recognition programs use machine learning to learn rules for converting speech to text
Examples of Bias and Unexpected Results¶
as machine learning becomes more popular and appears in more applications, examples of how it can go wrong have started to appear, e.g.
- a program to learn to play Tetris was told essentially to “minimize penalty points”, and so it learned to pause the game
- a program to play 5-in-a-line variant of Tic Tac Toe on an infinite board learned that it could win by placing its pieces at locations with addresses that were so large they crashed the other players, which was counted as a win
- a program to land an airplane “gently” learned that if the airplane flew at full speed into the landing area it would end up landing gently — due to an arithmetic overflow
- Microsoft’s Tay chatbot famously learned to chat by mimicking its users, and it soon degraded into uttering offensive (e.g. racist) statements when users discovered it could be gamed
- a program for predicting repeat offenders determined that black people had a
higher change of re-offending than non-black people
- while that might be an accurate appraisal of the data the system was trained on, any system that comes to a conclusion along racial lines for a topic like crime is likely going to be debated
- a facial recognition system work 99% of the time for white male faces, but only 35% for dark-skinned female faces
these examples serve as a reminder that “learning” is not some magical technique that will solve all your problem
it is just one tool of many that a programmer/engineer might use to solve a problem, and its has pros and cons just like any solution
they also show some of the unusual problems that can arise in ML systems that you need to be on the lookout for
- telling an ML system what exactly to learn can be very difficult!
Main Categories of Machine Learning¶
one common way to categorize ML methods is by what kind of data they take as input
Supervised Learning¶
supervised learning: the input is a set of instances labeled with the correct result
- for example, spam filters are supervised learners: they learn from analyzing email that has already been labeled spam or ham
- when new spam is flagged, it can update its rules
- another example is to predict the price of, say, a second-hand car given a list of attributes (such as brand, age, mileage, …)
- the input to this learner would be lists of features and prices
- note here that the goal is to learn to predict the price, which is a numeric quantity; in contrast, the spam filter is learning one of two values, “ham” or “spam”
- this example of learning to predict the price of an example of regression
some important supervised learning algorithms are: k-nearest neighbors, linear regression, logistic regression, support vector machines (SVMs), decision trees, random forests, and neural networks
Unupervised Learning¶
unsupervised learning takes only data as input, and no other help (e.g. no training set of correctly labeled data)
- one kind of unsupervised learning is clustering, i.e. analyze the data to see if it somehow can be divided into related clusters
- for example, a technology review website might be able to use clustering to learn about its readers, e.g. maybe that 60% of readers work in tech and visit the site at least once a weekday, while 10% are not in tech and visit the site on average once a week
- a clustering algorithm does not know any groups ahead of time: it only gets to see the unlabelled input data
- association rule learning finds interesting relations between attributes
- for example, by looking at sales receipts a supermarket might be able to determine which items tend to be purchased together, e.g. it might turn out that people who buy milk and orange also tend to buy cereal
some algorithms for unsupervised learning include k-means clustering, and various types of neural networks designed for unsupervised learning
Semi-supervised Learning¶
semi-supervised learning is a learner that can use both labeled and non-labeled data
- typically a combination of supervised and unsupervised learning
for example, a photo website might use unsupervised clustering to notice that the same person happens to appear in 5 different photos, and then used supervised classification to assign a name to that person
Reinforcement Learning¶
in reinforcement learning the learner performs an action in an environment (often a virtual environment), and is rewarded if the action is good, and penalized if the action is bad
- the learner uses a policy to pick its action
- the policy is modified after each penalty and reward
- the goal is to find a policy that maximizes rewards
- AlphaZero is an example of reinforcement learning: it plays chess moves,
using a policy to choose moves
- it gets penalties and rewards from whether it wins or lose games
- it updates its policy network after each reward/penalty
reinforcement learning is quite different than supervised/unsupervised learning
- reinforcement learning requires an environment (perhaps simulated) in which the agent can act so that it can get rewards/penalties for its actions
- supervised/unsupervised learning needs just input data: there is no need for actions or an environment
reinforcement learning could even be treated as an overall approach to AI in general
Batch Learning and Online Learning¶
some learning systems are batch learners or offline learners, i.e. they require all there input be given to them at once in one big batch
- this can cause storage problems and performance problems
online learners learn incrementally, i.e. they can take their input in increments, and you can get results after only some input has been given to the system
- typically, the more input the system sees, the better it performs
- since online learners get their input over time, they often have parameters that you can set for how much of impact older input has compared to newer input
Tools for Learning¶
ML has become a popular as a mainstream programming technique in the last few years
often big data, visualization, and ML go together
companies like Google have made efficient ML libraries freely available, and there are now many tutorials and courses where you can learn all the details
practical ML learning involves things like:
- getting data
- ML repositories with standard test sets can easily be found online
- you can also find large amounts of raw data at other websites, or generate
data in your own applications meant for later learning
- e.g. a web log might keep track of everyone who visits it so that later ML can, say, discover patterns in visitors
- “cleaning” data and putting it into a format your algorithms can use
- data might have missing attributes or unusual formats
- you may need (or want) to change some data, e.g. maybe your data has raw times like “8:41:am” and “7:09pm”, but you could decide to simplify it into categorical data like “morning”, “afternoon”, and “night”
- determining parameters to use for your learning algorithms
- most learning algorithms still require humans to play with different parameters/techniques and see what gives the best results
- you also have to decide what learning algorithms to use at all
- different techniques are best for different domains
- visualizing the input and output is often important in real life, so you
usually want a way to produce good-looking charts, graphs, and tables
- Jupyter notebooks is one popular tools that is often used for data exploration
- it lets you mix code, text, and images onto a single web page
- it is good when you want to automate, or partially automate, your ML
“pipeline”
- in contrast, a spreadsheet is generally much harder to automate, and is mostly useful for smaller data sets that can be processed by hand
- learning all this is a lot of work!
- takes practice and experience to get good at this
- if you also want to learn how the algorithms actually work (instead of just calling them from a library), that would be even more work