Rating Predictor
A Multiclass classifier which can predict the sentiment of the text fragment along a scaled range from 1 to 5 stars. Most of the models predict the polarity of the text such as: positive or negative sentiment, but not subjective opinions along a multiclass continum.
Feature Selection

Data preprocessing is a technique that involves transforming raw data into an understandable format The data was preprocessed using NLTK library and the following tasks were performed to clean the data:
- All punctuations and digits were removed
- All stopwords were removed
- All text was converted into lowercase
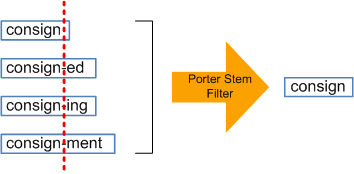
- Performed data stemming, i.e reduced inflected words to their stem, base or root form
- Changed the encoding format to UTF-8
Feature Transformation
TF.IDF
- TF.IDF stands for term frequency-inverse document frequency is a measure that intends to reflect how important a word is to document in a collection. It is often used as a weighing factor in information retrieval and text mining. It can be used for stop-words filtering in various subject fields. It is composed of two terms : Term-frequency and Inverse Document Frequency Term-frequency (TF) – It measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in a long document as compared to shorter ones TF(t) = Number of times term t appears in a document / Total number of terms in the document
- Inverse document frequency (IDF) : Measures how important a term is. While computing TF, all terms are given importance. However, there are certain terms which may appear a lot of times but have very little importance. Hence, it is important to weigh down the frequent terms while scale up the rare ones. This is done in the following way IDF(t) = log_e(Total number of documents / Number of documents with term t in it)
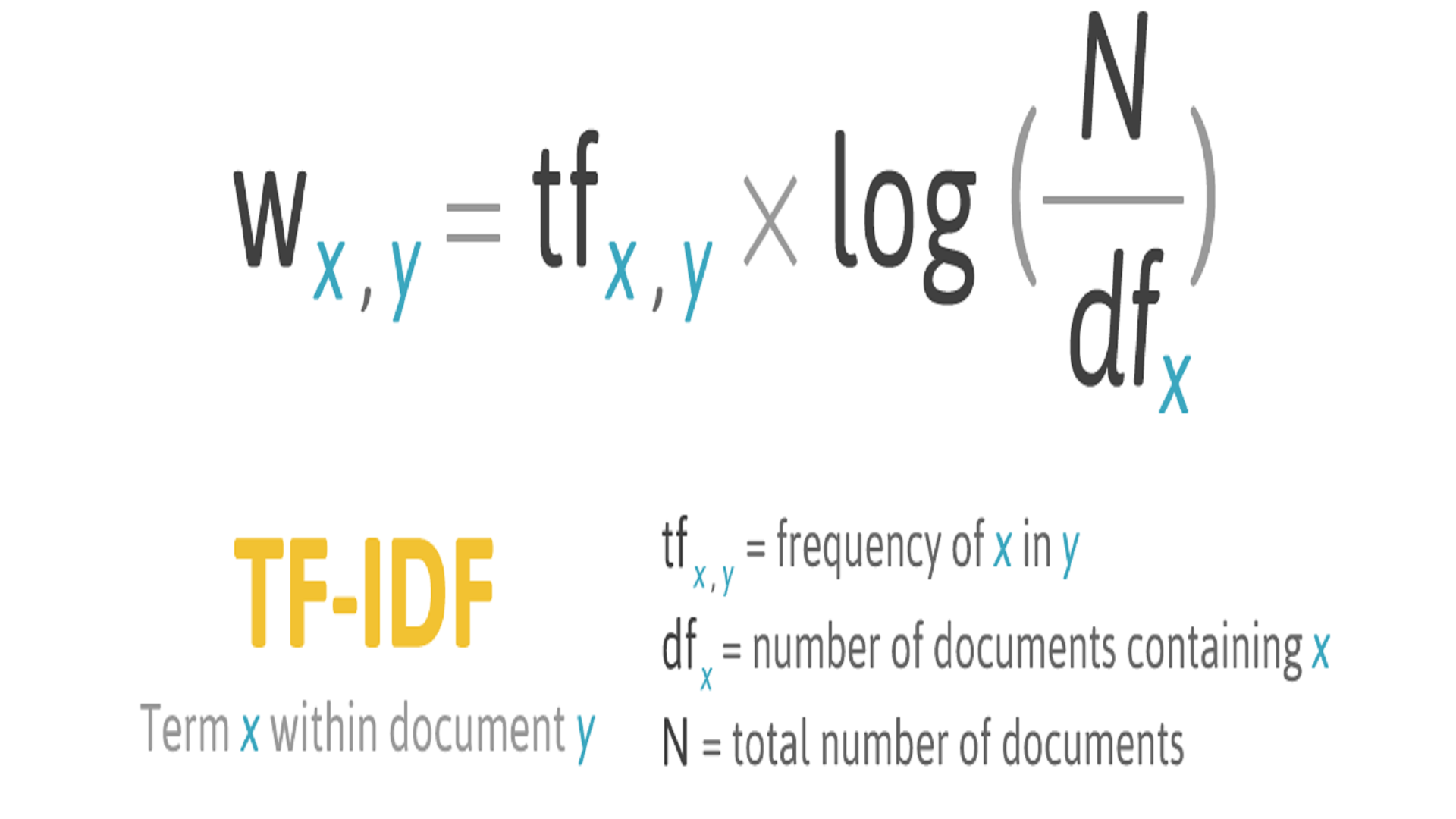
Model
Naive Bayes Classifier
- The Naive Bayesian classifier is based on Bayes’ theorem with independence assumptions between predictors. A Naive Bayesian model is easy to build, with no complicated iterative parameter estimation which makes it particularly useful for very large datasets. Despite its simplicity, the Naive Bayesian classifier often does surprisingly well and is widely used because it often outperforms more sophisticated classification methods.
- Bayes theorem provides a way of calculating the posterior probability, P(c|x), from P(c), P(x), and P(x|c). Naive Bayes classifier assume that the effect of the value of a predictor (x) on a given class (c) is independent of the values of other predictors. This assumption is called class conditional independence.
- P(c|x) is the posterior probability of class (target) given predictor (attribute).
- P(c) is the prior probability of class.
- P(x|c) is the likelihood which is the probability of predictor given class.
- P(x) is the prior probability of predictor.
- Training data and test data was 80:20 percent of the total data
- Accuracy achieved was 59% on training and 54% on test data
Algorithm
