To assess the evidence against the manufacturers claim you make
that claim the null hypothesis: ![]() and
and ![]() .
We use a z test (large sample size, known
.
We use a z test (large sample size, known ![]() ) and get
) and get
![]()
The alternative predicts large negative z so the P-value is the area under the normal curve to the left of -3 or about 0.0013. The conclusion is that this P-value is so small that the manufacturer's claim is not credible; the packages are underweight.
![]()
For ![]() you get P = 0.004 and for
you get P = 0.004 and for ![]() you get P=.996.
The first P-value means there is strong evidence against
you get P=.996.
The first P-value means there is strong evidence against ![]() while the
second means there is little or no evidence against
while the
second means there is little or no evidence against ![]() . The
clear real world conclusion is that the concentration of cadmium in the lake is
virtually certain to be over 200.
. The
clear real world conclusion is that the concentration of cadmium in the lake is
virtually certain to be over 200.
This conclusion summarizes the statistical calculations which rested on some assumptions. In practice there are serious potential problems which should be examined by the investigator (subject matter specialist not the statistician). Are the measurements unbiased? Are they independent or were they made in batches which would show more homogeneity within a batch than between? Are you really measuring the average concentration in the whole lake or only in a part of it?
- The area to the left of 1.645 under a standard normal curve is
95% so a 90% confidence interval is given by the range
 or
or  .
. - The multiplier changes from 1.645 to 1.75.
- You must solve the inequalities as follows

and similarly for the other inequality to get

so that the two things on the outside are the interval.
- The lengths of the intervals are
 times
in one case
times
in one case  and in the other
and in the other  . For
. For  these lengths are
3.92 and 4.02 so that the usual interval is shorter. (It is
a theorem that using
these lengths are
3.92 and 4.02 so that the usual interval is shorter. (It is
a theorem that using  produces the shortest interval.)
produces the shortest interval.)
![]()
which is, as the text warns, quite wide. The sample size is not terribly large and you might worry about the normal approximation but for a rough idea the normal approximation is ok.
- The null hypothesis of correct calibration is that
 and the alternative is that it is not.
and the alternative is that it is not. - The probability of recalibration is 1 minus the probability that the
sample average is between 9.8968 and 10.1032, that is,

In this part you are told to take
and get

- Now you take
 and get
and get

and then
 and get
and get  .
. - You made this calculation in b above and got c=2.58.
- Just by using n=10 in computing z. No change to c - that's the point of computing z.
- This average can be computed by subtracting 10 and multiplying
by 1000 to get the numbers -19, 6, -143, 107, -112, -207, -272, 439,
214 and 190 whose sum is 203 so
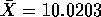 with n=10 so that
z = 0.32 and the hypothesis is not rejected at the 1% level.
with n=10 so that
z = 0.32 and the hypothesis is not rejected at the 1% level. - Recalibrate if |Z| > 2.58.