Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The TPSPLINE Procedure |
Penalized least squares estimates provide a way to balance fitting the data closely and avoiding excessive roughness or rapid variation. A penalized least squares estimate is a surface that minimizes the penalized least squares over the class of all surfaces satisfying sufficient regularity conditions.
Define xi as a d-dimensional covariate vector, zi as a p-dimensional covariate vector, and yi as the observation associated with (xi, zi). Assuming that the relation between zi and yi is linear but the relation between xi and yi is unknown, you can fit the data using a semiparametric model as follows:
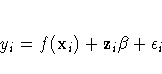
This model consists of two parts.
The ![]() is the parametric part of the
model, and the zi are the regression variables. The
f(xi) is the nonparametric part of the model,
and the xi are the smoothing variables.
is the parametric part of the
model, and the zi are the regression variables. The
f(xi) is the nonparametric part of the model,
and the xi are the smoothing variables.
The ordinary least squares method estimates f(xi) and
![]() by minimizing the quantity:
by minimizing the quantity:
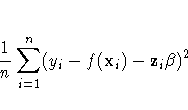
However, the functional space of f(x) is so large that you can always find a function f that interpolates the data points. In order to obtain an estimate that fits the data well and has some degree of smoothness, you can use the penalized least squares method.
The penalized least squares function is defined as

The first term measures the goodness of fit and
the second term measures the smoothness associated with
f. The ![]() term is the smoothing parameter, which governs
the tradeoff between smoothness and goodness of fit. When
term is the smoothing parameter, which governs
the tradeoff between smoothness and goodness of fit. When
![]() is large, it heavily penalizes estimates
with large second derivatives. Conversely, a small value
of
is large, it heavily penalizes estimates
with large second derivatives. Conversely, a small value
of ![]() puts more emphasis on the goodness of fit.
puts more emphasis on the goodness of fit.
The estimate ![]() is selected from a reproducing
kernel Hilbert space, and it can be represented as a linear
combination of a sequence of basis functions. Hence, the
final estimates of f can be written as
is selected from a reproducing
kernel Hilbert space, and it can be represented as a linear
combination of a sequence of basis functions. Hence, the
final estimates of f can be written as
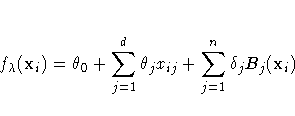
where Bj is the basis function, which depends on where
the data xj is located, and ![]() and
and ![]() are the coefficients that need to be estimated.
are the coefficients that need to be estimated.
For a fixed ![]() , the coefficients
, the coefficients ![]() can be estimated by solving an n×n system.
can be estimated by solving an n×n system.
The smoothing parameter can be chosen by minimizing the generalized cross validation (GCV) function.
If you write

![V(\lambda)=\frac{(1/n)||({I}-{A}(\lambda)){y}||^2}
{[(1/n)tr({I}-{A}(\lambda))]^2}](images/tpseq16.gif)
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.