Chapter Contents
Previous
Next
|
Chapter Contents |
Previous |
Next |
| The MODEL Procedure |
The MODEL procedure analyzes models in which the relationships among the variables comprise a system of one or more nonlinear equations. Primary uses of the MODEL procedure are estimation, simulation, and forecasting of nonlinear simultaneous equation models.
PROC MODEL features include
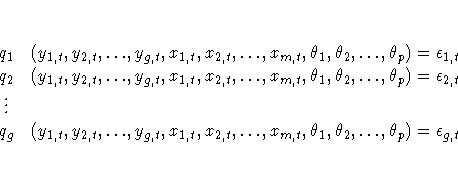




One method to remove simultaneous equation bias, in the linear case, is to replace the endogenous variables on the right-hand side of the equations with predicted values that are uncorrelated with the error terms. These predicted values can be obtained through a preliminary, or "first stage," instrumental variable regression. Instrumental variables, which are uncorrelated with the error term, are used as regressors to model the predicted values. The parameter estimates are obtained by a second regression using the predicted values of the regressors. This process is called two-stage least squares.
In the nonlinear case, nonlinear ordinary least-squares estimation is performed iteratively using a linearization of the model with respect to the parameters. The instrumental solution to simultaneous equation bias in the nonlinear case is the same as the linear case except the linearization of the model with respect to the parameters is predicted by the instrumental regression. Nonlinear two-stage least squares is one of several instrumental variables methods available in the MODEL procedure to handle simultaneous equation bias.
When you have a system of several regression equations, the
random errors of the equations can be correlated.
In this case, the large-sample efficiency of the estimation
can be improved by using a joint generalized least-squares method that takes
the cross-equation correlations into account. If the equations
are not simultaneous (no dependent regressors), then
seemingly unrelated regression (SUR) can be used.
The SUR method requires an estimate of the cross-equation error
covariance matrix, ![]() .The usual approach is to first fit the equations using OLS,
compute an estimate
.The usual approach is to first fit the equations using OLS,
compute an estimate ![]() from the OLS residuals,
and then perform the SUR estimation based on
from the OLS residuals,
and then perform the SUR estimation based on ![]() .The MODEL procedure estimates
.The MODEL procedure estimates ![]() by default, or you can supply
your own estimate of
by default, or you can supply
your own estimate of ![]() .
.
If the equation system is simultaneous, you can combine the 2SLS and SUR methods to take into account both simultaneous equation bias and cross-equation correlation of the errors. This is called three-stage least squares or 3SLS.
A different approach to the simultaneous equation bias problem is the full information maximum likelihood, or FIML, estimation method. FIML does not require instrumental variables, but it assumes that the equation errors have a multivariate normal distribution. 2SLS and 3SLS estimation do not assume a particular distribution for the errors.
Once a nonlinear model has been estimated, it can be used to obtain forecasts. If the model is linear in the variables you want to forecast, a simple linear solve can generate the forecasts. If the system is nonlinear, an iterative procedure must be used. The preceding example system is linear in its endogenous variables. The MODEL procedure's SOLVE statement is used to forecast nonlinear models.
One of the main purposes of creating models is to obtain an understanding of the relationship among the variables. There are usually only a few variables in a model you can control (for example, the amount of money spent on advertising). Often you want to determine how to change the variables under your control to obtain some target goal. This process is called goal seeking. PROC MODEL allows you to solve for any subset of the variables in a system of equations given values for the remaining variables.
The nonlinearity of a model creates two problems with the forecasts: the forecast errors are not normally distributed with zero mean, and no formula exits to calculate the forecast confidence intervals. PROC MODEL provides Monte Carlo techniques, which, when used with the covariance of the parameters and error covariance matrix, can produce approximate error bounds on the forecasts.
|
Chapter Contents |
Previous |
Next |
Top |
Copyright © 1999 by SAS Institute Inc., Cary, NC, USA. All rights reserved.